In recent times, there has been a surge of interest in leveraging Large Language Models (LLMs) and more specifically, Specific Language Models (SLMs) for creating powerful QnA systems and Chatbots. With significant developments in the field of NLP, these advanced language models have opened up new possibilities for various use cases. As someone who has already utilized cloud services in Azure and AWS for building Bots and QnA systems, I was intrigued to dive deeper into the world of LLMs and SLMs, conducting a detailed study and Proof of Concept (POC) to unlock their full potential. This article serves as a compilation of my findings, including code snippets and insights into these models from the very basics to more advanced scenarios. The goal is not just to provide generic code snippets, but to thoroughly explain the crucial aspects of creating QnA systems and bots using a variety of language models.
Best would be to study below link in the sequence they are.
looking to deploy azure functions on Aks or any other Kubernetes environment? follow the below blog I wrote recently to get the bare minimum needed to get this going.
We don’t need azure arc or any other service to achieve this. Connection to azure storage may be needed for some scenarios but not for HTTP triggered functions.
Every now and then, I come up with small projects so that I pickup the latest cloud tech and get some hands on experience. Codename ORION (dont as me why :/), I ll describe the problem statement below, what POC I did, and what is the future state I envision to get a hands on experience to as many azure cloud services as possible. All the post regarding the work done on this project will be tagged (Orion) #x .
Problem statement –
I am big into stock markets. Never had a hobby, but if a part time stock market trading is one, then that’s mine. After spending years in Indian stock market, I recently decided to try my luck in US stocks. With a broad number of platforms now available in Australia to trade USA stocks and options at low or zero fees, there was no better time. But very soon after going deep in USA stocks, I found I was out of time on my reading. Social media and some other stock forums are a goldmine, filled up with many detailed analysis and stock tips. Not all of them are true. Social media is used left and right for stock manipulation. But occasionally, there are few good tips too, from people who genuinely want to help. And I can confirm that from my personal experience.
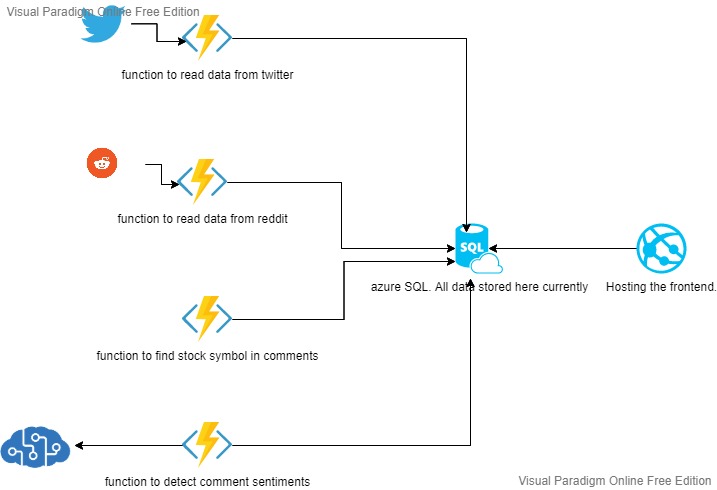
Now the problem. Currently I am following over 50 twitter and reddit accounts, and have bookmarked tons more on YouTube and eToro. Who the heck knew YouTube will give stock market tips in future. As a rule, I don’t want to spend more than 30 minutes daily reading on stocks, so I thought of using some azure cognitive services to see if I can cut down on my reading time and results have been good. As part of POC, what I basically did is to extract data from all the twitter and reddit accounts I follow, identity what stock are being mentioned in the comments/tweets/posts, and then run sentiment analysis on top of it to pick up the positive sentiment stocks. That way, whenever I am short on time, I can just pick the most discussed positive stock and start doing analysis on that. The results of the POC have been good. See this report with some data coming in –
Now I want to leverage this project to not only help me out by cutting down on my reading part, but also use this as an opportunity to learn some new azure services that I have been aiming to do some hands on skilling. The current state of the POC is like this
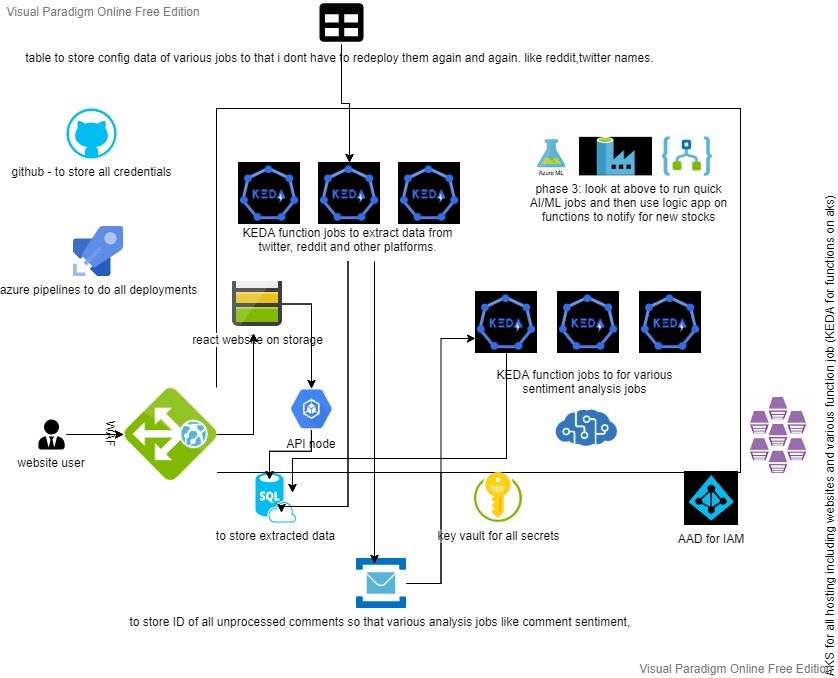
pretty basic from what you see above. I ll now slowly start changing this to below target state. That would also help me scale this to lot of other social media sites and forums. Currently the POC used just twitter and reddit.
Most important change to current state would be use of KEDA to run azure functions on AKS. Also see where I can leverage the new logic apps on container offering. Will also try to deploy some other services to AKS if possible like API gateways and SQL on containers and monitor its stability ahead, later being a stateful deployment and not the usual stateless kubernetes deployment.
for every change done, I ll try to write a blog it out for anyone keen to get some hands on experience on above tech.
something similar can always be done by any business to capture user sentiments on various social media platforms and then tie back those comments/sentiments to a particular team/product/offering rather than assuming the sentiment is towards an entire brand.
Issue description –
Network connectivity doesn’t work with Windows 2003 VMs in Azure
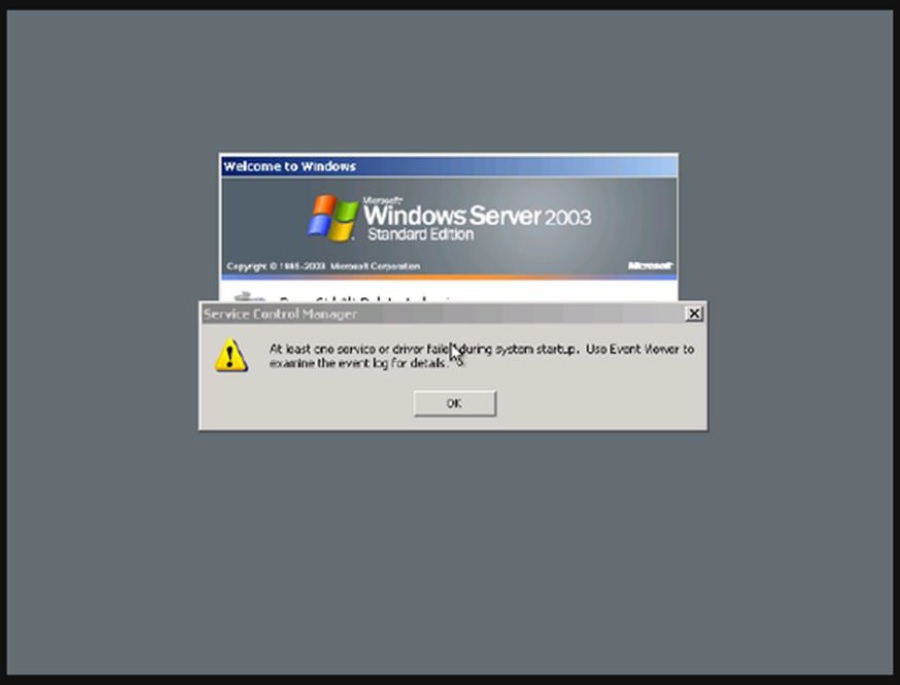
In some cases, you may observe network connectivity issue with Windows Server 2003 virtual machine in Azure after migration from on-premises VMWare infrastructure. Symptoms –
1. You are not able to ping, RDP or telnet on any port to the migrated virtual machine within /or across subnet.
2. You will see ‘Welcome to Windows’ screen in the ‘Boot diagnostics’ feature in Azure platform. (Note: You may get ‘Service control Manager’ screen as well.)
Cause – This issue occurs as Hyper-V integration services were not installed on the VM before migration.
Resolution – The following methods will help to resolve the network connectivity issue in Azure with Windows Server 2003 after migration activity. Method 1: – Use GP Settings to install Hyper-V Integration Services during Startup operation.
Pre-requisites to resolve network connectivity issue using Method 1:
1. Windows 2012/2012 R2 Hyper-V Guest integration services – Download Windows server 2012R2/2012 Hyper-V Guest integration services from this link . OR If you have a Hyper-V 2012 environment you can get the installer from C:\Windows\System32\vmguest.iso. Mount the iso file and copy the installer folder to the Windows Server 2003 VM to be migrated.
Resolution Steps:
1. Login to Windows Server 2003 VM with administrator credentials (i.e. to be migrated VM in your VMWare environment)
2. Copy Hyper-V Guest integration services installer under C:\HyperV folder.
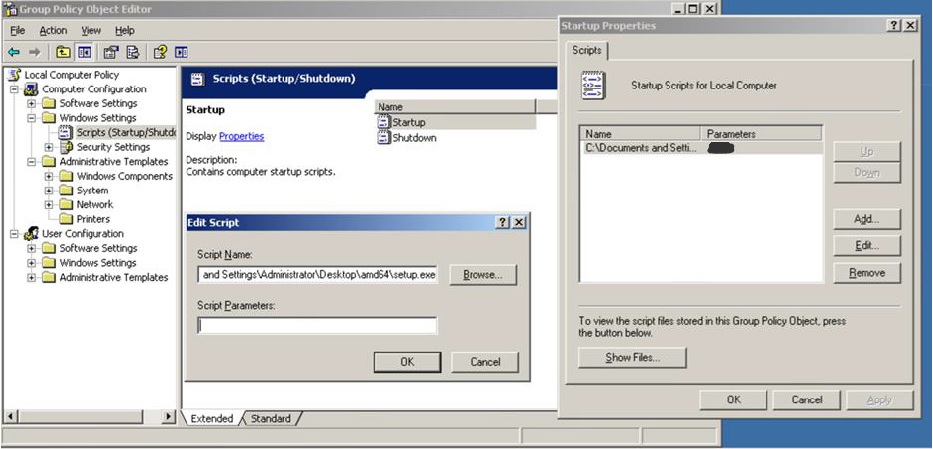
3. Below are details to create GP settings:
– Run -> gpedit.msc
– “Computer Configuration” -> “Windows Settings” -> “Scripts (Startup/Shutdown)”
– Open Startup -> Add -> select setup.exe from C:\HyperV folder in the “Script Name”
Note: You won’t be able to install guest integration services directly on the virtual machine that is running on VMware farm.
4. The above Startup task will install the Hyper-V Guest components on the first boot in Azure. If required, reboot VM twice to ensure integration services comes in effect on the virtual machine.
Method 2: – Install Hyper-V Integration Services manually on Windows Server 2003 using Windows 2016 Hyper-V Host in Azure.
In certain cases, GP settings Startup task may not work on the migrated VM. If that happens, then you can follow steps listed under Method 2 to install Hyper-V integration services manually on Windows Server 2003.
Pre-requisites to resolve network connectivity issue using Method 2:
1. Windows 2012/2012 R2 Hyper-V Guest integration services – Download Windows server 2012R2/2012 Hyper-V Guest integration services from this link . OR If you have a Hyper-V 2012 environment you can get the installer from C:\Windows\System32\vmguest.iso. Mount the iso file and copy the installer folder to the Windows Server 2003 VM to be migrated.
2. Create Windows 2016 Hyper-V virtual machine in Azure (Reference article: https://docs.microsoft.com/en-us/azure/virtual-machines/windows/nested-virtualization).
3. Local Admin credentials of migrated Windows Server 2003
Resolution Steps:
1. Migrate Windows Server 2003 VM from VMWare on-premise environment to Azure using Azure Migrate tool.
2. Download OS disk of migrated Windows Server 2003 VM to HyperV Host server under C:\Win2003 folder
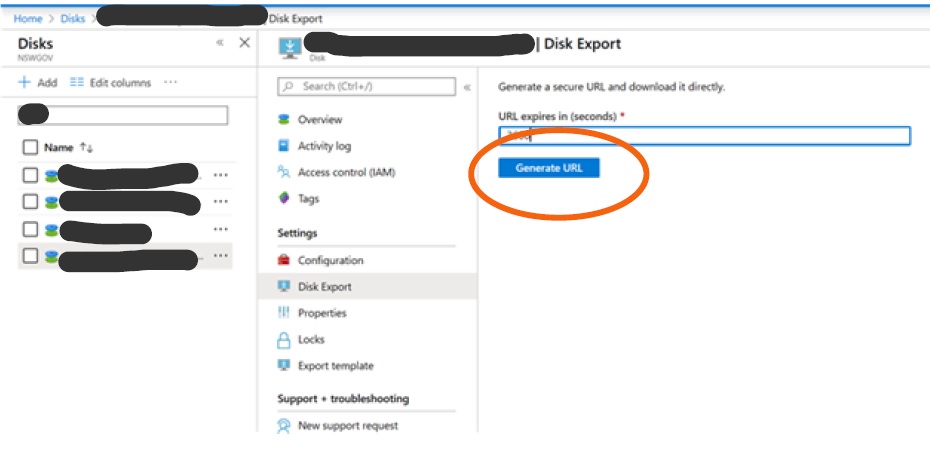
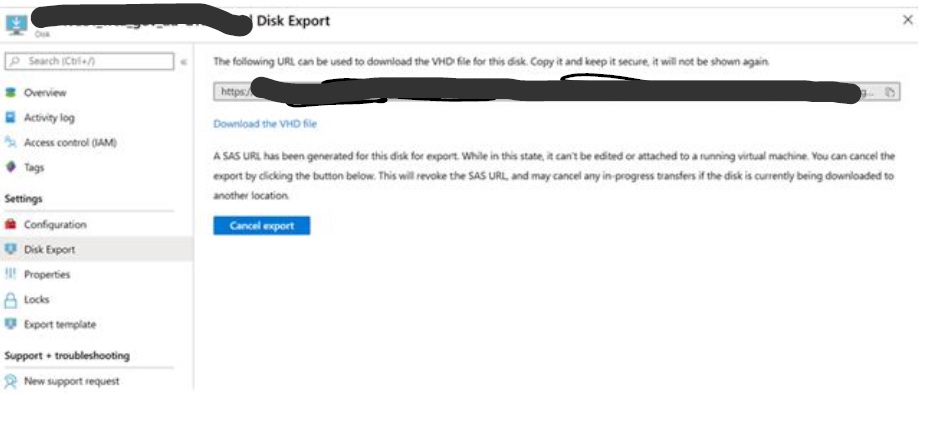
– Login to Azure Portal → Deallocated Windows 2003 VM → Locate the attached OS disk in the portal and Select ‘Disk Export’ option -> Click ‘Generate URL’ to download VHD file from Azure Subscription to Hyper-V host (Server Name: W2k16HyperV).
– Copy URL to download the VHD file to Hyper-V Host (Server Name: W2k16HyperV)
– Login to W2k16HyperV server – Open Internet Explorer – Type the URL in the address bar that you had copied in the previous step to download the VHD file (OS disk) of Win 2003 VM and save that file under C:\Win2003 folder.
Note: Ensure that the downloaded file extension is ‘.vhd’. If required, you can change the file extension to .vhd after the download process has been completed.
3. Create a New VM in Hyper-V Manager using downloaded Win 2003 OS VHD
– Open Hyper-V Manager on W2k16HyperV server and create a New VM by selecting boot disk (C drive) that you’ve download in the Step 2.
– Power-on / Start VM in Hyper-V Manager.
Note: This New VM, i.e. Win2003 VM may not detect your mouse in the remote session, so you’ll have to use keyboard.
Reference article: https://docs.microsoft.com/en-us/windows-server/virtualization/hyper-v/get-started/create-a-virtual-machine-in-hyper-v
4. Login to this Win2003 VM with local admin credentials and install HyperV integration services from C:\HyperV folder – Run Setup.exe file.
Note: This New VM, i.e. Win2003 VM may not detect your mouse in the remote session, so you’ll have to use keyboard.
– Reboot Win2003 VM after installation process has been completed.
– Login to Win2003 server -> Open cmd -> Run “Ipconfig” command and confirm that result contain 169.254.x.x. IP address. (Note: Your mouse should work after installing HyperV integration services)
– Shutdown/Power-off VM if you can see 169.254.x.x as a result of ipconfig command.
5. Open Powershell -> Login to Azure using your credentials
– Ensure you’re connected to the right subscription by using Set-Azcontext command
– Next step is, to upload Win2003 OS disk wherein you’ve successfully installed Hyper-V integration services in Step 4.
Note: If necessary, change required variables / parameters in below commands to match with folder name, RG name and disk name etc.
————————————————————–
– If there are no errors observed while executing above commands, then upload Win2003 OS disk by using AzCopy command. Reference article: https://docs.microsoft.com/en-us/azure/storage/common/storage-use-azcopy-v10
AzCopy.exe copy “C:\Win2003\Win2k3.vhd” $diskSas.AccessSAS –blob-type PageBlob
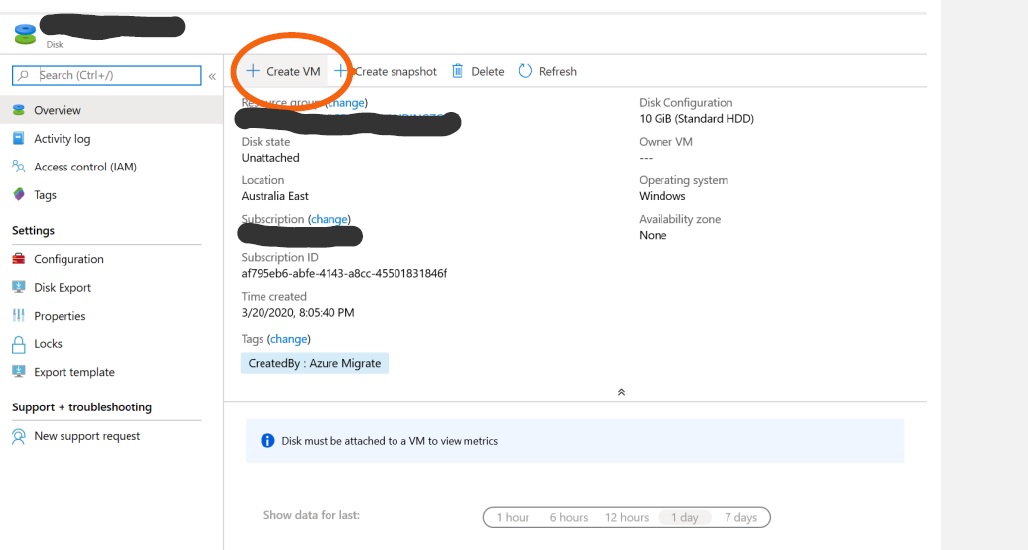
6. Login to Azure Portal with your credential. Locate the disk (Powershell script had disk name variable) that you’ve uploaded in the subscription in the previous ‘Step 5’.
– Select the uploaded Win2003 OS disk – click on ‘Create VM’ and follow the wizard to provision VM.
– Ensure you attach all data disks that you’ve migrated for the respective VM while creating the new VM.
– Power-on this VM and validate networking connectivity to/from within subnet and across subnet.
I have few of my own AKS clusters that run my custom wordpress, .NET Core and php website. The other day I decided to integrate Azure AD with it, since RBAC was already enabled, and decided to give a namespace to a friend to try out few things. Since I did not want to give him full rights, I decided to integrate AAD, make a new dev Namespace and only give him access to this namespace. On how to do this is straight forward.
You can go to this link to setup AAD integration. https://docs.microsoft.com/en-us/azure/aks/azure-ad-integration
but don’t create a new cluster. Here we are aiming to update existing one. Once all the prerequisite is done, use this command to update you existing aks cluster to enable AAD integration. az aks update-credentials \ –resource-group myResourceGroup \ –name myAKSCluster \ –reset-service-principal \ –service-principal $SP_ID \ –client-secret $SP_SECRET — no-wait
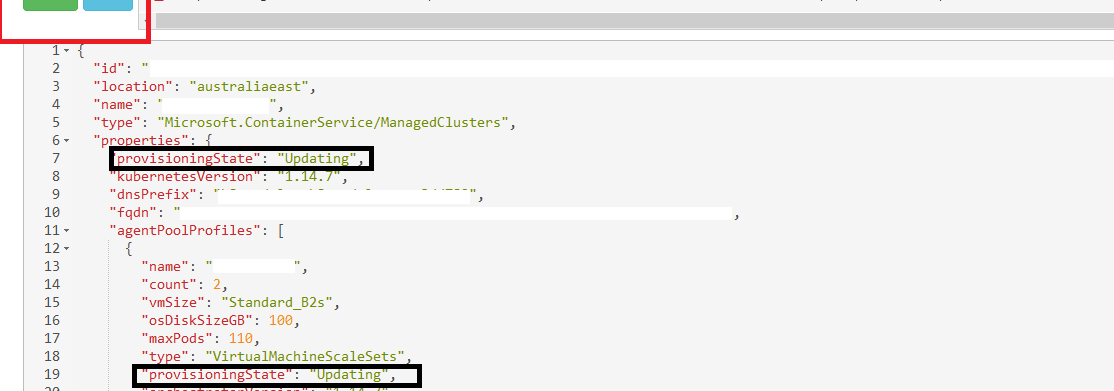
once you run this command, you want to see that the status of the cluster ProvisioningState is succeeded to confirm command ran successfully. to do this, run command below
a@Azure:~$ az aks show –resource-group xxxx –name xxxx –output table
even if you run this command multiple times, you will see same status RefreshingAADProfile and after few hours this may go to Failed State.
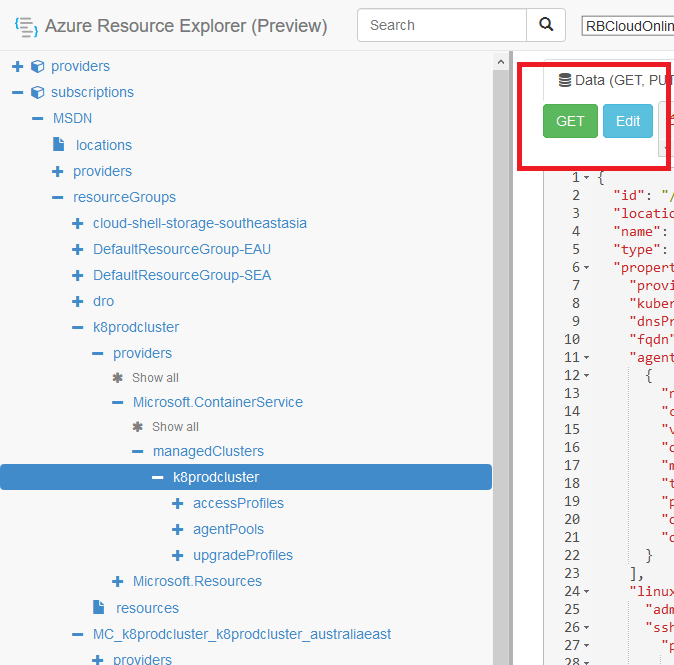
Whats more wierd is when you will run below command, you can see in the json that AAD integration is not null anymore and credentails are updated. a@Azure:~$ az aks show –resource-group xxxx –name xxxx
once you do that, click on edit and change from GET to POST.
Once you do that, change these to values from Failed State to Succeeded. (Ignore the Updating in image above, I took snapshot later. you will see Failed for below 2 settings.)
Once you change the value from Failed to Succeeded, and Click on Put, you will see cluster on azure portal will go to Updating status again, and then will finally go to Succeeded status again.
In the ever-evolving landscape of artificial intelligence, having access to powerful language models has become crucial for a wide range of applications. Thanks to META’s groundbreaking decision to make Llama 2 open source and available for commercial use, developers now have the freedom to harness the potential of this advanced language model without any external dependencies. In this blog post, we will explore how Llama 2 has paved the way for on-premise usage and its potential to revolutionize the field of private AI.
What is Llama 2?
Llama 2, developed by META, is an advanced language model that has been made open source for developers and businesses alike. With this move, META has enabled the community to download the model and access the code for various Llama (LLM) use cases on-premise. Furthermore, developers can also utilize the same code base in the public cloud, offering them a range of flexible options to work with.
Independence from External Services
One of the primary advantages of adopting Llama 2 is its independence from platforms like OpenAI or Palm2. With Llama 2 available offline, developers no longer need to rely on external services for their language processing needs. This autonomy not only streamlines the development process but also eliminates the requirement of sending sensitive data to third-party cloud endpoints. By keeping data processing in-house, users gain more control over their data, enhancing privacy and security.
Comparing Llama 2 to OpenAI Offerings
A crucial aspect that makes Llama 2 even more attractive is its competitiveness with leading language models, including those from OpenAI. For users who may wonder about the capabilities of Llama 2 compared to OpenAI’s GPT-4, there is a detailed comparison available at “openaimaster.com/llama-2-vs-gpt-4.” The insights provided in this comparison highlight Llama 2’s potential and make it evident that it can stand toe-to-toe with some of the best language models in the market.
Real-World Testing and Accuracy
To further understand the capabilities of Llama 2, a real-world test was conducted using a 200-page PDF document. The results were highly accurate, demonstrating the effectiveness and precision of Llama 2 for complex language processing tasks. As the model can be downloaded, developers can now achieve such impressive results without any reliance on external servers.
Conclusion
With the availability of Llama 2 as an open-source and commercially usable language model, developers now have the freedom to innovate and experiment with advanced natural language processing. This breakthrough from META empowers users to utilize Llama 2 on-premise or in the public cloud, without relying on external AI services. The model’s remarkable accuracy, combined with the ease of implementation and data privacy benefits, positions Llama 2 for widespread adoption in various industries. As the journey of private AI progresses, Llama 2 serves as a beacon of hope, unlocking the potential for developers to create their own private GPT solutions.
Code snippet
you can use the code below to test out Llama 2 trained on your document. It uses FAISS as vector DB. I have extended it to support multiple use cases. You each deployment has a separate index file in FAISS and you can have multiple bots using the same APIs for QnA. The llama model is used from here to support CPU only systems for POC. https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/blob/main/llama-2-7b-chat.ggmlv3.q8_0.bin
from langchain.llms import CTransformers
from langchain.llms import CTransformers
def build_llm():
# Local CTransformers model
llm = CTransformers(
model="models/llama-2-7b-chat.ggmlv3.q8_0.bin",
model_type="llama",
config={"max_new_tokens": 256, "temperature": 0.01},
)
return llm
utilities
from langchain import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from src.llm import build_llm
def set_qa_prompt(qa_template=None):
"""
Prompt template for QA retrieval for each vectorstore
"""
if not qa_template:
qa_template = """Use the following pieces of information to answer the user's question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Context: {context}
Question: {question}
Only return the helpful answer below and nothing else.
Helpful answer:
"""
prompt = PromptTemplate(
template=qa_template, input_variables=["context", "question"]
)
return prompt
def build_retrieval_qa(llm, prompt, vectordb):
dbqa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectordb.as_retriever(search_kwargs={"k": 2}),
return_source_documents=False,
chain_type_kwargs={"prompt": prompt},
)
return dbqa
def setup_dbqa(faiss_path):
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
)
vectordb = FAISS.load_local(faiss_path, embeddings)
llm = build_llm()
qa_prompt = set_qa_prompt()
dbqa = build_retrieval_qa(llm, qa_prompt, vectordb)
return dbqa
main code
# Import necessary libraries
from flask import Flask, request
import os
import shutil
from build_vector_db import build_faiss_db
from src.utils import setup_dbqa
from werkzeug.utils import secure_filename
# Create the Flask app
app = Flask(__name__)
# Define a route and corresponding view function
@app.route("/train", methods=["POST"])
def train():
user_id = request.form["user_id"]
deployment_id = request.form["deployment_id"]
USER_UPLOAD_FILE_DIR = f"uploaded_files/{user_id}/{deployment_id}"
USER_PROCESSED_FILE_DIR = f"processed_files/{user_id}/{deployment_id}"
FAISS_INDEX_DIR = f"faiss_index_files/{user_id}/{deployment_id}"
if not os.path.exists(FAISS_INDEX_DIR):
os.makedirs(FAISS_INDEX_DIR)
build_faiss_db(USER_UPLOAD_FILE_DIR, FAISS_INDEX_DIR)
for filename in os.listdir(USER_UPLOAD_FILE_DIR):
# Move the file to USER_PROCESSED_DIR
file_path = os.path.join(USER_UPLOAD_FILE_DIR, filename)
if not os.path.exists(USER_PROCESSED_FILE_DIR):
os.makedirs(USER_PROCESSED_FILE_DIR)
new_file_path = os.path.join(USER_PROCESSED_FILE_DIR, filename)
shutil.move(file_path, new_file_path)
return "Training Successfully Done"
# Define a route and corresponding view function
@app.route("/upload", methods=["POST"])
def upload():
user_id = request.form["user_id"]
deployment_id = request.form["deployment_id"]
files = request.files.getlist("files")
USER_DIR = f"uploaded_files/{user_id}"
DEPLOYMENT_DIR = f"{USER_DIR}/{deployment_id}"
if files[0].filename == "":
return "Please select the pdf file."
else:
if not os.path.exists(DEPLOYMENT_DIR):
os.makedirs(DEPLOYMENT_DIR)
for file in files:
filename = secure_filename(file.filename)
file.save(f"{DEPLOYMENT_DIR}/{filename}")
return "files saved successfully"
# Define a route and corresponding view function
@app.route("/query", methods=["POST"])
def query():
user_id = request.form["user_id"]
deployment_id = request.form["deployment_id"]
question = request.form["question"]
FAISS_INDEX_DIR = f"faiss_index_files/{user_id}/{deployment_id}"
dbqa = setup_dbqa(FAISS_INDEX_DIR)
response = dbqa({"query": question})
return response["result"]
# Define a route and corresponding view function
@app.route("/remove", methods=["POST"])
def delete():
user_id, deployment_id = request.form["user_id"], request.form["deployment_id"]
FAISS_INDEX_DIR = f"faiss_index_files/{user_id}/{deployment_id}"
USER_PROCESSED_FILE_DIR = f"processed_files/{user_id}/{deployment_id}"
os.remove(FAISS_INDEX_DIR)
os.remove(USER_PROCESSED_FILE_DIR)
return "Successfully Deleted"
# Run the app if this script is executed directly
if __name__ == "__main__":
app.run(debug=True)
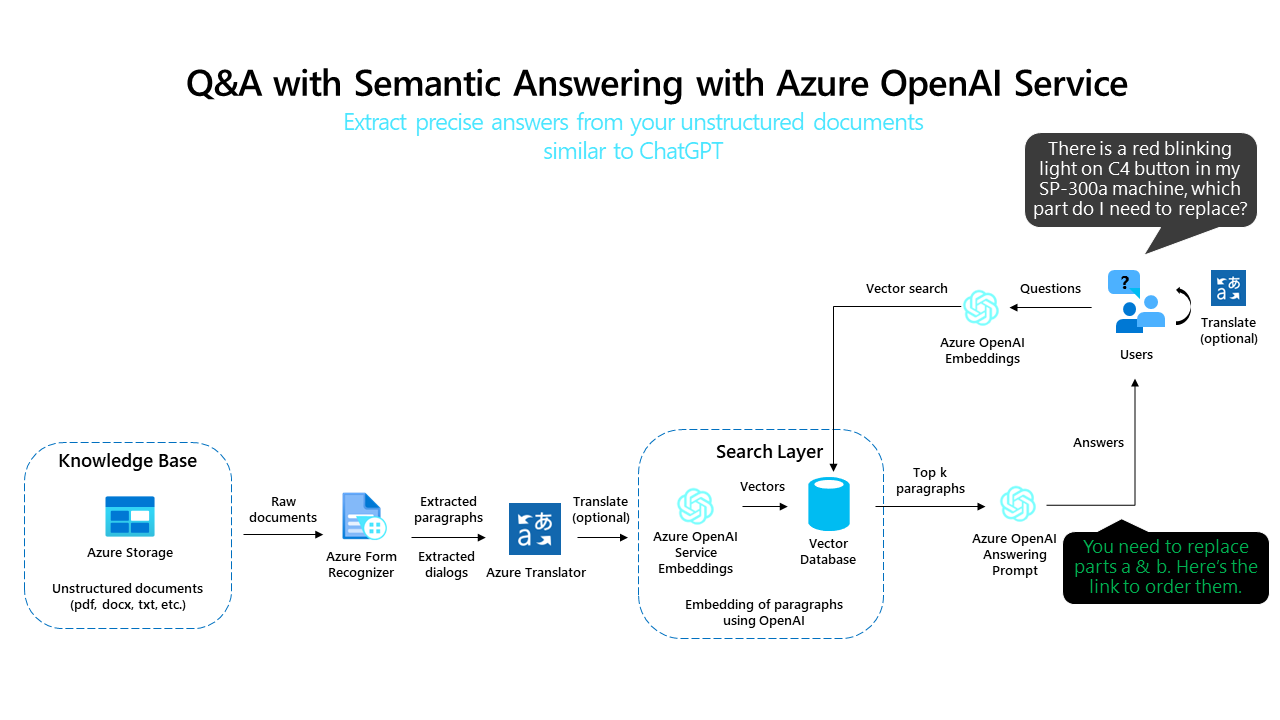
so once you do the code changes, you can use the same python code to make QnA bots. During my learnings, I also came across few articles by azure team. The ones below would be of interest to Azure developers as it uses native PAAS services for vector databases. These repos pretty much do it all for QnA bot within azure using Azure Open AI offerings.
This repo uses Azure OpenAI Service for creating embeddings vectors from documents. For answering the question of a user, it retrieves the most relevant document and then uses GPT-3 to extract the matching answer for the question.
I exposed my query section using APIs and this is how the response looks like below. IT IS NOT GENERATED FROM OPEN AI. BUT IS RATHER FROM THE WIKI ARTICLE I UPLOADED AS PDF. So you can essentially use the same code to QnA your own documents.
Open AI now has a strong data usage policies and guidelines. It is getting safer to train your data on open AI.
Starting on March 1, 2023, we are making two changes to our data usage and retention policies:
OpenAI will not use data submitted by customers via our API to train or improve our models, unless you explicitly decide to share your data with us for this purpose. You can opt-in to share data.
Any data sent through the API will be retained for abuse and misuse monitoring purposes for a maximum of 30 days, after which it will be deleted (unless otherwise required by law).
below are the results I obtained using openAI and it was pretty accurate based on the document I uploaded.
curl --location 'http://xx.xx.xx.xx:81/query' \
--form 'user_id="35"' \
--form 'deployment_id="4"' \
--form 'prompt="You are a qna bot. You need to answer the query on the basis of document provided. If the answer is not contained within the text below, say \"Sorry, I don'\''t know. Please try again. P:{documents}Q:{query} A:"' \
--form 'question="when was bangladesh formed"'
Bangladesh was formed on December 16, 1971.
curl --location 'http://xx.xx.xx.xx:81/query' \
--form 'user_id="35"' \
--form 'deployment_id="4"' \
--form 'prompt="You are a qna bot. You need to answer the query on the basis of document provided. If the answer is not contained within the text below, say \"Sorry, I don'\''t know. Please try again. P:{documents}Q:{query} A:"' \
--form 'question="can you summarize what happened in 8th century"'
In the 8th century, several significant events took place. Charlemagne established the Carolingian Empire, with Aix-la-Chapelle as its de facto capital. The Franks conquered Aquitania, Gascony, Lombardy, and Bavaria. The Khmer Empire was established by Jayavarman II. The Kingdom of Pamplona (later Navarre) and the Kingdom of Scotland (Alba) were formed. The Uyghur Khaganate was destroyed by the Kyrgyz. The Treaty of Verdun divided the Carolingian Empire into West, Middle, and East Francia. The March of Tuscany was established, and the Chimú Empire emerged in South America. The Vikings established the Kingdom of Dublin, and the Kingdom of Brittany was established. Middle Francia was further divided into the Kingdom of Italy, Lotharingia, and the Kingdom of Provence.
I ll upload the code snippet for it later as I am doing lot of modifications to it to make it production ready and take care of multiple Bots from a single codebase by leveraging pinecone indexes.
The code can be broken down into following steps.
Uploading a PDF file. Here I am also using user_ID and deployment_ID as parameters so that same source can be used to store documents from various users for different QnA bots
def upload():
user_id = request.form["user_id"]
deployment_id = request.form["deployment_id"]
files = request.files.getlist("files")
USER_DIR = f"uploaded_files/{user_id}"
DEPLOYMENT_DIR = f"{USER_DIR}/{deployment_id}"
if files[0].filename == "":
return "Please select the pdf file."
else:
if not os.path.exists(DEPLOYMENT_DIR):
os.makedirs(DEPLOYMENT_DIR)
for file in files:
filename = secure_filename(file.filename)
file.save(f"{DEPLOYMENT_DIR}/{filename}")
return "files saved successfully"
PDF Text Extraction. After that the next step is to take text from PDFs and prepare it for chunks. Chucks are parts of PDFs as we dont upload the entire file together but in chucks as per OpenAI limits.
def get_pdf_text(file_path):
text = ""
# for pdf in pdf_docs:
pdf_reader = PdfReader(file_path)
for page in pdf_reader.pages:
text += page.extract_text()
return text
Text Chunking. This is how we prepare various code chunks after reading the PDFs
def chunks(iterable, batch_size=100):
"""A helper function to break an iterable into chunks of size batch_size."""
it = iter(iterable)
chunk = tuple(itertools.islice(it, batch_size))
while chunk:
yield chunk
chunk = tuple(itertools.islice(it, batch_size))
def split_text_into_chunks(text, chunk_size=500):
words = text.split()
text_chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i : i + chunk_size])
text_chunks.append(chunk)
return text_chunks
Batch Upsert to Pinecone. Once we have the chunks, we save them to our vector database.
def batch_upsert(text_chunks, user_id, deployment_id, batch_size=10):
try:
# create vectors to upsert
vectors_to_upsert = []
for chunk in tqdm(text_chunks):
id = uuid.uuid4().hex
chunk_embedding = get_embedding(chunk)
vectors_to_upsert.append((id, chunk_embedding, {"text": chunk}))
# upsert in batches
batch_size = 10
for i in tqdm(range(0, len(vectors_to_upsert), batch_size)):
batch = vectors_to_upsert[i : i + batch_size]
pinecone_index.upsert(
vectors=batch, namespace=f"namespace_{user_id}_{deployment_id}"
)
return True
except Exception as e:
print("Exception in batch upsert ", str(e))
return False
And finally we query against the vectors in database and use openAI to get the right answers.
def get_response_from_openai(query, documents, prompt):
"""Get ChatGPT api response"""
# prompt = get_prompt_for_query(query, documents)
print("prompt1", prompt)
print(query)
prompt = prompt.format(documents=documents, query=query)
print("prompt2", prompt)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0,
max_tokens=800,
top_p=1,
)
return response["choices"][0]["message"]["content"]
def get_prompt_for_query(query, documents):
"""Build prompt for question answering"""
template = """
You are given a paragraph and a query. You need to answer the query on the basis of paragraph. If the answer is not contained within the text below, say \"Sorry, I don't know. Please try again.\"\n\nP:{documents}\nQ: {query}\nA:
"""
final_prompt = template.format(documents=documents, query=query)
return final_prompt
def search_for_query(user_id, deployment_id, query, prompt):
"""Main function to search answer for query"""
query_embedding = get_embedding(query)
query_response = pinecone_index.query(
namespace=f"namespace_{user_id}_{deployment_id}",
vector=query_embedding,
top_k=3,
include_metadata=True,
)
documents = [match["metadata"]["text"] for match in query_response["matches"]]
documents_as_str = "\n".join(documents)
response = get_response_from_openai(query, documents_as_str, prompt)
return response
My focus for POC (Proof of Concept) lies in few key models. Three of them are in the public cloud space, 3 are open source and then the OpenAI models.
Rather than writing lengthy articles on the open-source ones, it’s best to guide you to one of the best links. Hugging Face manages an LLM leaderboard and has a lot of details around it. It’s best to refer to this link: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
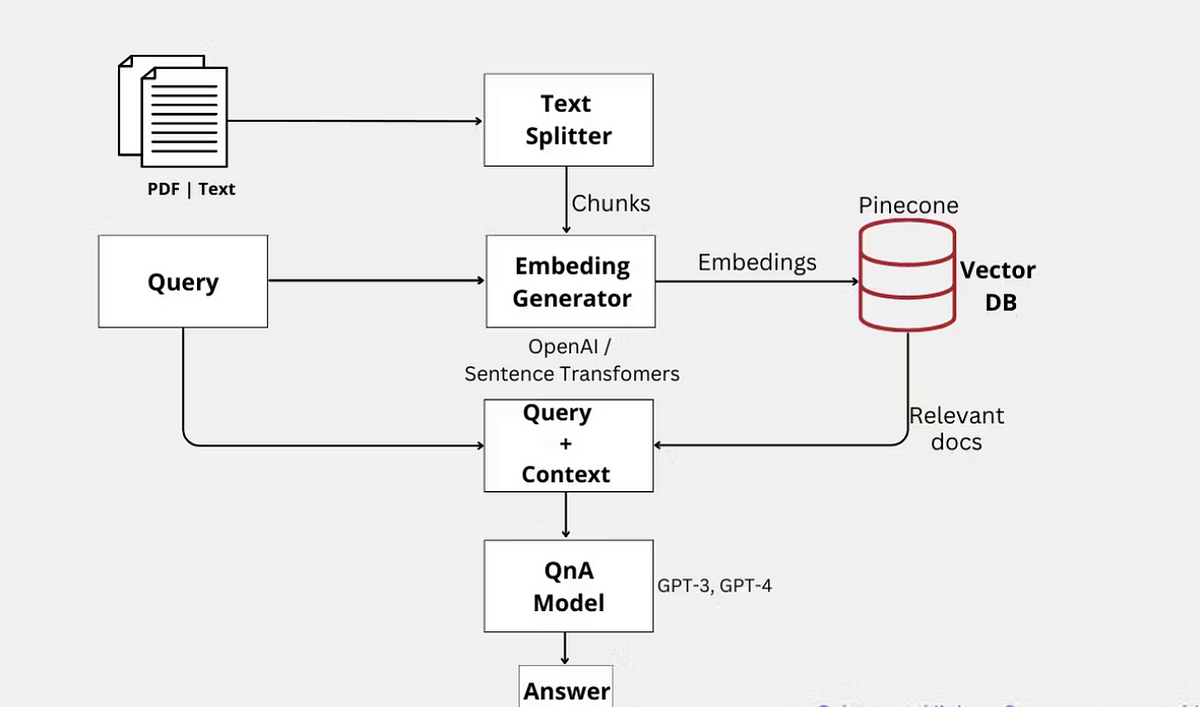
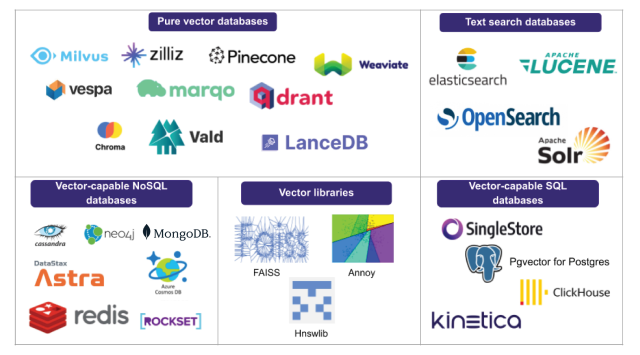
Understanding Vector Databases: In the realm of computer science, a vector database is a specialized storage system that organizes and retrieves data in the form of high-dimensional vectors. A vector is a mathematical representation of data, where each element corresponds to a feature or attribute. These databases leverage vector-based indexing and retrieval techniques, making them highly efficient in handling large-scale datasets with complex structures.
The key principle behind vector databases lies in the notion that similar items or entities are closer to each other in the vector space. This proximity allows for the swift retrieval of similar data, making vector databases exceptionally valuable for similarity searches, recommendation systems, and, in our case, Q&A bots.
Significance and Applications: Vector databases hold profound importance in various domains due to their ability to handle complex data structures and similarities. Some prominent applications include:
a. Similarity Searches: Vector databases excel in performing similarity searches, where they can efficiently locate similar items, texts, or images within a vast dataset. This capability is invaluable for content-based retrieval in Q&A bots, where similar questions or answers need to be identified quickly.
b. Recommendation Systems: E-commerce platforms and streaming services leverage vector databases to build powerful recommendation engines that suggest relevant products, movies, or music based on users’ preferences and historical interactions.
c. Personalization: In marketing and user engagement, vector databases assist in creating personalized experiences by analysing user behaviour and matching them with relevant content.
d. Natural Language Processing (NLP): NLP tasks, like sentiment analysis, text classification, and language translation, can be significantly enhanced by employing vector databases to represent and process textual data effectively.
Popular Vector Databases: Several powerful vector databases have emerged, each offering unique features and functionalities to cater to specific needs. Some of the leading vector databases are:
a. Faiss: Developed by Facebook AI Research, Faiss is an efficient and widely adopted library for similarity search and clustering tasks. Its GPU acceleration capabilities enable lightning-fast retrieval, making it a preferred choice for large-scale applications.
b. Annoy: Short for “Approximate Nearest Neighbors Oh Yeah,” Annoy is a lightweight, easy-to-use library that focuses on approximate nearest neighbour search. It provides fast and scalable solutions, making it suitable for real-time applications like Q&A bots.
c. Milvus: An open-source vector database, Milvus, is specifically designed for handling large-scale vector data. Its user-friendly interface and support for diverse vector types make it an ideal choice for NLP-based applications like Q&A bots.
Vector Databases in Q&A Bots: Integrating vector databases into Q&A bots unlocks several benefits, including:
a. Faster Retrieval: When a user poses a question, the Q&A bot can quickly search for similar questions or known answers within its vector database. This leads to faster response times, improving the overall user experience.
b. Enhanced Accuracy: By identifying similar questions, the bot can present previously verified answers, ensuring higher accuracy and reducing the likelihood of erroneous responses.
c. Personalized Responses: Vector databases enable Q&A bots to understand user preferences and history, allowing them to tailor responses based on individual preferences.
d. Scalability: As the Q&A bot’s knowledge base grows, vector databases can efficiently manage and retrieve information, ensuring scalability without compromising on performance.
Conclusion:
Vector databases have revolutionized the world of data storage and retrieval, offering unparalleled speed and accuracy in handling complex data structures. In the context of Q&A bots, vector databases enable faster, more accurate responses by efficiently identifying similar questions and known answers. As the technology continues to advance, vector databases will play an increasingly critical role in enhancing the capabilities of AI-powered applications, opening doors to new possibilities in natural language processing and beyond.
1. OpenAI (the company or the provider or AI models)
Established in 2015, OpenAI stands at the forefront of AI research and development. Its mission is to ensure that artificial general intelligence (AGI) benefits all of humanity. OpenAI actively collaborates on projects across various domains, from robotics to language processing, striving to create advanced technologies that are safe, accessible, and beneficial for society.
2. ChatGPT: Advancing Conversational AI (the product made by OpenAI)
ChatGPT is one of OpenAI’s most remarkable achievements in the domain of conversational AI. Powered by the GPT (Generative Pre-trained Transformer) architecture, ChatGPT is a sophisticated chatbot that engages in dynamic conversations with users. The model is trained on extensive datasets, enabling it to generate coherent and contextually appropriate responses. This capability has made ChatGPT highly valuable for applications in QnA systems and chatbots.
3. LLM (Large Language Model): Empowering Language Understanding and Generation (the models used by ChatGPT)
LLM, or Large Language Model, refers to AI models like GPT-3, which is among the largest and most powerful language models developed by OpenAI. LLMs are trained on vast datasets comprising diverse text sources, which allows them to understand and generate human-like language effectively. These models exhibit astonishing prowess in various language-related tasks, including QnA, machine translation, summarization, and content generation.
4. LongChain: Streamlining Communication Between AI Models (the technology used in creating chatGPT and many other samples using LLM)
LongChain is an innovative technology developed by OpenAI to enhance communication and collaboration among different AI models. By creating a chain-like structure, LongChain facilitates seamless information transfer and context-sharing between models. This capability is especially crucial for QnA and chatbots, as it enables them to draw upon a broader range of knowledge, resulting in more accurate responses and improved user experiences.
Question-Answering (QnA) systems leverage AI technologies, such as ChatGPT and LLM, to provide precise and relevant answers to user queries. These systems process the user’s questions, analyze the context, and retrieve information from vast knowledge bases. With advancements in AI, QnA systems have become invaluable resources in educational platforms, customer support, and even virtual assistants like voice-activated chatbots.
Chatbots are AI-driven virtual assistants designed to simulate human-like conversations with users. They harness sophisticated language models like ChatGPT to interpret and respond to user inputs in real-time. With the ability to understand context, Chatbots can engage users in meaningful dialogues, whether it’s for customer service interactions, online support, or entertainment purposes.
7. Generative AI (no it’s not just chatting or QnA)
What is Generative AI? Generative AI enables users to quickly generate new content based on a variety of inputs. Inputs and outputs to these models can include text, images, sounds, animation, 3D models, or other types of data.
There are various types of QA systems, but they can generally be grouped into two main categories: (i) open-domain QA and (ii) closed-domain QA.
Open-domain QA systems are designed to answer questions on any topic and rely on vast amounts of unstructured text data available publicly on the internet e.g., Wikipedia. In contrast, closed-domain QA systems are specialized for specific domains, such as healthcare or legal, and require a structured knowledge base for accurate responses. Another approach to QA is information retrieval (IR)-based QA, which involves retrieving relevant documents from a corpus and extracting answers from them. This method can be used in both open and closed-domain QA systems, depending on the type of corpus used.
In addition to open and closed-domain QA, there are two other types of QA tasks: extractive and abstractive. Extractive QA extract answers directly from a given text or corpus in the form of spans, while abstractive QA generate answers using natural language generation techniques, often paraphrasing or summarizing information from the text.
DONT JUST UPLOAD DOCUMENTS TO LLM APIs to get answers. Study how vector databases work and can help you get better performance and less tokens.
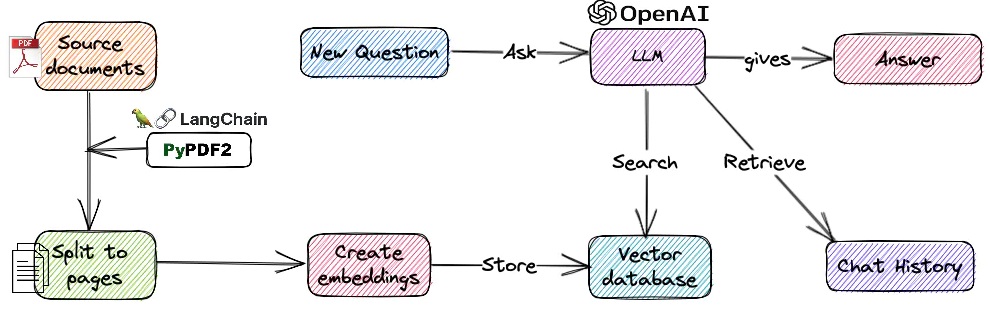
If you harness the power of LLMs with vector databases together, you can create large scale production ready bots or QnA systems. Before we see the code snippets ahead, let’s see the steps in creating QnA bot with vector databases and LLMs.
Language Model (LLM) Initialization:
The QnA bot uses a pre-trained language model (such as GPT-3.5) to comprehend and generate human-like text.
The LLM is loaded and ready to process user queries.
User Query Input:
The bot receives a natural language question or query from the user.
Query Preprocessing:
The input query is preprocessed to remove any irrelevant or sensitive information and convert it into a format suitable for the next steps.
Vector Representation:
The preprocessed query is encoded into a vector representation using techniques like word embeddings or transformer-based embeddings (e.g., BERT, RoBERTa).
The vector representation captures the semantic meaning and contextual information of the query.
Vector Database Query:
The vector representation of the user query is used to search the vector database.
The vector database contains embeddings of relevant documents or passages, typically created using similar embedding techniques as used for the query.
Candidate Retrieval:
The vector database returns a set of candidate documents or passages that are potentially relevant to the user query.
These candidates are ranked based on their similarity to the query vector.
Answer Generation:
For each candidate document or passage, the QnA bot retrieves the corresponding text content.
The LLM is used to read and understand the content, extracting relevant information that can potentially answer the user’s query.
Scoring and Ranking:
The candidate answers are scored based on their relevance and quality.
The scoring can be based on factors like LLM confidence in generating the answer, relevance to the user query, and other contextual information.
Answer Selection:
The answer with the highest score is selected as the final response to the user.
If the confidence in the top answer is below a certain threshold, the bot may present multiple potential answers or ask for clarification.
Response to User:
The selected answer is presented to the user as the response to their original query.
Feedback Loop (Optional):
Some QnA bots may incorporate a feedback loop, allowing users to rate the accuracy and helpfulness of the provided answers.
This feedback can be used to improve the system’s performance over time by re-ranking candidate answers or updating the vector database.
Continual Learning (Optional):
To keep the QnA bot up-to-date, the system can be trained with new data regularly or incrementally.
New data may include additional user queries and corresponding correct answers.